
目录
前言
环境准备
- Anaconda
记得选择添加到环境中(会有红色提示的那个),安装完成后在 cmd 中用
conda --version测试 - CUDA 安装完成后这个路径应该会有这个文件:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\bin\mvcc.exe此为 CUDA 程序的编译器,在 cmd 中使用
nvcc --version命令来测试。
如果重启 cmd 后此命令还不生效,检查一下环境变量中是否添加了上面的路径(到 bin 的路径) - PyTorch 使用生成的命令进行安装。
笔记本上安装完以后一直不生效(提示 DLL 不可用)视频里确实提到过要 1050Ti 而笔记本上的是 1050。总之,卸载重装,用 pip 卸载重装无数次后,能用了,但是是 cpu 版本的,gpu 仍不可用。我决定先用着,看看能进行到哪一步。
# 测试代码 import torch print(torch.__version__) print(f"gpu: {torch.cuda.is_available()}")
回归问题
一些离散的点,存在于坐标中,肉眼可见应该是一条穿过点云中间的斜线。
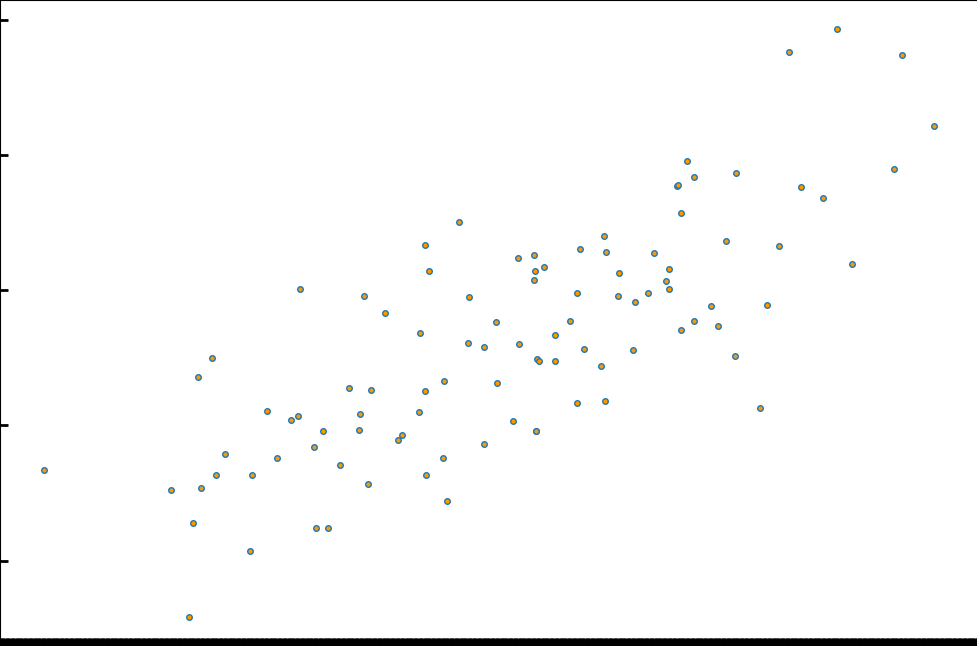
所以斜线应为 y = kx + b,根据教程,我们使用 y = wx + b。
现在我们想求出斜线的公式,将点的 x,y 作为数据输入,此时 x,y 为已知量,100 个点就得到了 100 个方程。这样我们就可以求解方程组来解出 w 和 b 的值。由于无法用一条直线完全连接所有的点,因此我们要找到一个最接近的直线解,用方差来验证结果,方差越小说明我们得到的 w,b 越符合预期。对于每一个点,我们可以理解为点到直线有误差,即:y = wx + b + eps。于是得到公式 loss = (y - wx - b)^2。
而回归算法的核心就是如何找到下一个点,将 loss 分别对 w 和 b 求偏导,再将 x,y 带入得到求导之后的差,作为变化量加入到原先的 w/b 中得到新的 w/b。
new_b = b + loss'b = b + 2(y - wx - b)new_w = w + loss'w = w + 2(y - wx - b)x
实际代码中需要将所有点的变化量求平均值,再乘上梯度值作为变化量:
# 获取梯度信息
def step_gradient(b_current, w_current, points, learningRate):
b_gradient, w_gradient = 0, 0
N = float(len(points))
for i in range(len(points)):
x, y = points[i]
# loss = (wx + b - y)^2
# 对 b 求导 loss'b = 2(wx + b - y)
b_gradient += -(2/N) * (y - (w_current*x + b_current))
# 对 w 求导 loss'w = 2x(wx + b - y)
w_gradient += -(2/N) * (y - (w_current*x + b_current)) * x
new_b = b_current - learningRate*b_gradient
new_w = w_current - learningRate*w_gradient
return [new_b, new_w]
使用公式 sq = Σ(loss[x, y]) 来检查方差。
def compute_error_for_line_given_points(b, w, points):
totalError = 0
for i in range(len(points)):
x = points[i, 0]
y = points[i, 1]
totalError += (y - (w*x + b)) ** 2
return totalError/float(len(points))
完整代码
import numpy as np
# y = wx + b 方差 loss = Σ(y - wx - b)^2
def compute_error_for_line_given_points(b, w, points):
totalError = 0
for i in range(len(points)):
x = points[i, 0]
y = points[i, 1]
totalError += (y - (w*x + b)) ** 2
return totalError/float(len(points))
# 获取梯度信息
def step_gradient(b_current, w_current, points, learningRate):
b_gradient, w_gradient = 0, 0
N = float(len(points))
for i in range(len(points)):
x, y = points[i]
# loss = (wx + b - y)^2
# 对 b 求导 loss'b = 2(wx + b - y)
b_gradient += -(2/N) * (y - (w_current*x + b_current))
# 对 w 求导 loss'w = 2x(wx + b - y)
w_gradient += -(2/N) * (y - (w_current*x + b_current)) * x
new_b = b_current - learningRate*b_gradient
new_w = w_current - learningRate*w_gradient
return [new_b, new_w]
def gradient_descent_runner(points, starting_b, starting_w, learning_rate, num_iterations):
b, w = starting_b, starting_w
for i in range(num_iterations):
b, w = step_gradient(b, w, np.array(points), learning_rate)
return [b, w]
def run():
points = np.genfromtxt('data.csv', delimiter=',')
learning_rate = 0.0001
initial_b, initial_w = 0, 0
num_iterations = 1000
print(f"Starting gradient descent at b = {initial_b}, w = {initial_w}, error = {compute_error_for_line_given_points(initial_b, initial_w, points)}")
print("Running...")
b, w = gradient_descent_runner(points, initial_b, initial_w, learning_rate, num_iterations)
print(f"After {num_iterations} iterations b = {b}, w = {w}, error = {compute_error_for_line_given_points(b, w, points)}")
if __name__ == '__main__':
run()
可以看到:
run()函数首先读入所有的点的数据,并设置各种初始参数:learning_rate = 0.0001下降梯度,初学通常使用这个值,下降缓慢,计算结果较为准确。initial_b, initial_w = 0, 0设置初始的 b/w 值。num_iterations = 1000迭代次数为 1000 次,可以得到比较准确的结果。可以尝试修改这个值来查看结果,如设为 100 或 10000。
- 在迭代之前先查看一下初始的方差。
- 通过下降梯度算法得到学习之后的 b/w 的值。
- 在学习完成之后查看结果和新的方差,可以看到结果接近人类计算的值,并且方差降低了很多。
末尾闲言
Same as before,并不想在一个文章里放太大的信息量。写博客的人不好整理思绪,看文章的人更是不方便选择重点。由于找的视频是【入门】视频,本来还想一篇文章够了,谁知道单是装环境和理解算法就够我喝一壶了。
因此还是决定分段编写,以后自己需要查看的时候也方便。