
本文是关于线段树的 基础知识 的讲解,建树,求和,加减异或等操作
- 如果你对线段树完全不了解,建树时有一些疑惑,看本文有点不理解,可以试试先看一下 线段树啊建树方法与原理
- 如果你已经对于线段树的基础操作非常了解,请直接进入下一篇文章 线段树 + 离散化
有感而发
我在思考线段树如何进阶的时候看到了几句话,于是有感而发:
线段树实际上来说,确实不是一个算法,而是一个工具,而线段树也是我认为与 “数据结构” 这个词最相关的。它能够在很多场景将 O(n) 的复杂度降低到 O(logn) ,因此来说它是一个工具。但我认为这也是它对于新手来说难的原因,因为它能适用的情况太多了,因此变化多样。(就像扳手能扳的螺丝那天知道多少种是吧,撬棍能撬的门,窗,车胎啥的=w=)
目录
线段树的基础操作
上一节我们讲了很多关于线段树的建树原理,相信大家对于线段树这种数据结构已经有所了解,这一节关于线段树的操作由于经常用到 区间 的概念,所以这里放出来一张仿佛更直观的图
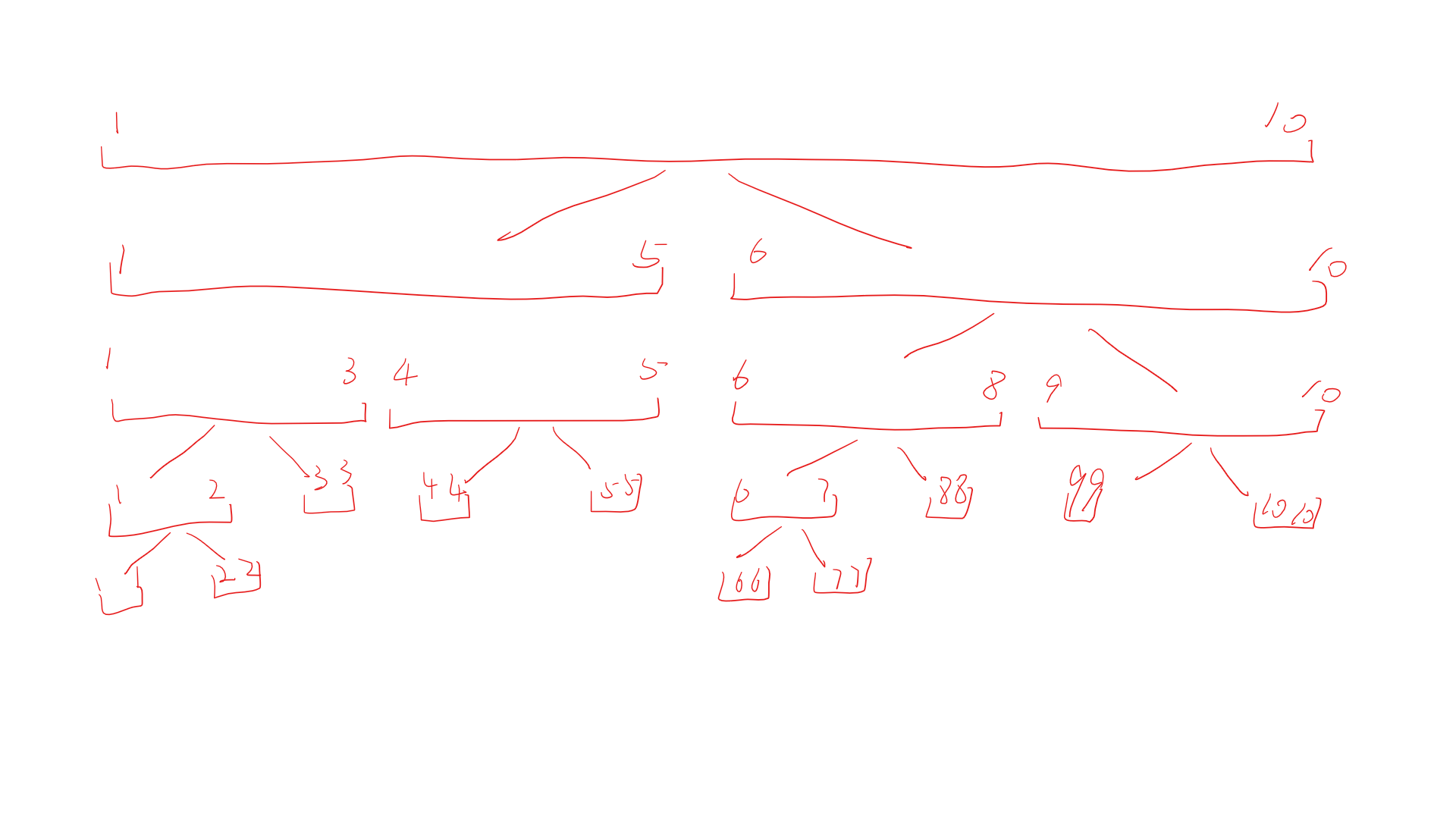
线段树最简单的有 求和线段树;最大最小值线段树 这么两种,我们先用这个 求和 线段树的模板题来开始:敌兵布阵 HDU-1166
这个题就是两种操作: 1、针对单个数据增减;2、针对一个连续区间求和。
那么对于这些操作,我们先来看一下第一个操作应该如何进行。由于我们要 维护 线段树,而上一节我们讲过线段树除了叶子节点,每个节点的值都是它所分出来的两个子节点的和,所以我们在改变叶子节点的值的时候要同时更新与它有关的节点(父节点)的信息。
这里我们把向上更新节点封装成一个函数 push_up(int t)
//继承上节的定义
#define MAXN int(5e4 + 9)
#define DEFI int l, int r, int t
#define INIF 1, n, 1
#define LSON l, (l + r) >> 1, t << 1
#define RSON ((l + r) >> 1) + 1, r, t << 1|1
int S[MAXN], T[MAXN << 2];
//向上更新 - 求和树就是将这一节点的值赋为这个节点的两个子节点的值的和
void push_up(int t) {
T[t] = T[t << 1] + T[t << 1|1];
//其实取最大值最小值只需要在这里换一下 push_up() 函数即可
//T[t] = max(T[t << 1], T[t << 1|1]);
//T[t] = min(T[t << 1], T[t << 1|1]);
return ;
}
// p 是第几个数,n 是改变的值
void update(int p, int n, DEFI) {
//如果遇到叶子节点,则为我们要更新的节点
if (l == r) {
T[t] += n;
return ;
}
//如果不是叶子节点,则向子节点递归
int m = (l + r) >> 1;
if (m >= p) update(p, n, LSON);
else update(p, n, RSON);
//更新过子节点后应该更新一下当前节点
push_up(t);
return ;
}
这里总结一下,线段树寻找子节点方法:
- 如果遇到叶子节点,则为我们要更新的节点
- 如果这个区间的 中点 在所求节点的 右边 ,那么就往左找
- 如果这个区间的 中点 在所求节点的 左边 ,那么就往右找
- 注意由于左子节点是 [l, m] ,右子节点是 [m + 1, r] ,因此条件 1 应该是
m >= p
学会了更新某一个数据的值,我们来看看怎么求区间的和,这个不太好理解
//返回一个整数,参数需要所求区间的左边界(L)和右边界(R)
int query(int L, int R, DEFI) {
if (L <= l && R >= r) return T[t];
int m = (l + r) >> 1, res = 0;
if (L <= m) res += query(L, R, LSON);
if (R > m) res += query(L, R, RSON);
return res;
}
总结如下,线段树的查询方法:
- 如果这个区间被完全包括在目标区间里面,直接返回这个区间的值
- 如果这个区间的左子区间和目标区间有交集,那么搜索左子区间
- 如果这个区间的右子区间和目标区间有交集,那么搜索右子区间
- 同样的由于右子区间是 [m + 1, r] ,因此判断条件是
R > m
稍难一点的基础操作
对于某些(简单)题,我们可能会遇到需要对一个区间内的所有元素都加上或减去某个数的操作。
这时候根据我们已经掌握的知识,我们可以先把每个需要更换的叶子节点都进行一次操作,然后再将相关的节点依次向上更新到顶端。这样做好像每一步都是很快捷的操作,但是当数据量变大的时候,实际上每次向上更新的时间都累加起来就会很多很多。对于更新一个数
| 普通求和 | 线段树求和 |
|---|---|
| 1 + n | 1 + logn |
但是对于更新一个区间的数,就变成了
| 普通求和 | 线段树求和 |
|---|---|
| n + n | n + n*logn |
会发现反而比普通的加一加还要费时,因此我们要想一个方法来优化这一点。
我们总结之前的操作会发现,线段树之所以优于线性求和的原因就是它能将 一段数据 当成 一个数据 来直接使用,所以在区间操作的时候我们也要继续这个思想,引出一个新概念: 懒标记 。
这个玩意我刚开始不知道叫什么,只是觉得思路好神奇,后来又见到了几次,感觉这个名字真形象。思路就是能跟新大区间先更新大区间,不更新下面的子节点,但是另开一个标记树标记一下,等之后用到下面的节点的时候如果标记树里有东西,再更新下面的节点,这样子就能做到依然是 “用到哪里走到哪里” 。
这么说可能比较抽象,先走代码
//一个节点对应一个标记,所以大小和树是一样的
int V[SMAX << 2];
//顺便一提有的人也会把树叫 tree[] ,懒标记叫 lazy[]
//数组叫什么是个人习惯哈,我喜欢用一个字母所以就这样了
void push_down(int t, int s) {
if (V[t]) {
V[t << 1] += V[t];
V[t << 1|1] += V[t];
T[t << 1] += V[t << 1]*(s - (s >> 1));
T[t << 1|1] += V[t << 1|1]*(s >> 1);
V[t] = 0;
}
return ;
}
void update(int L, int R, int n, DEFI) {
if (L <= l && R >= r) {
T[t] += n*(r - l + 1);
V[t] += n;
return ;
}
push_down(t, r - l + 1);
int m = (l + r) >> 1;
if (L <= m) update(L, R, n, LSON);
if (R > m) update(L, R, n, RSON);
push_up(t);
return ;
}
int query(int L, int R, DEFI) {
if (L <= l && R >= r) return T[t];
push_down(t, r - l + 1);
int m = (l + r) >> 1, res = 0;
if (L <= m) res += query(L, R, LSON);
if (R > m) res += query(L, R, RSON);
return res;
}
区间操作就和区间查询类似,总结区间更新的方法如下:
- 如果这个区间被完全包括在目标区间里面,直接更新管理这个区间的节点
- 如果这个区间的左子区间和目标区间有交集,那么向左子区间更新
- 果这个区间的右子区间和目标区间有交集,那么向右子区间更新
- 同样的由于右子区间是 [m + 1, r] ,因此判断条件是
R > m
注意:
- 在更新时,如果要向子区间更新,递归之前应先将懒标记传递下去
- 在查询时,查询子节点之前应先判断一下当前节点是否有没有更新的懒标记存在
更新 子节点 之后 需要 向上更新父节点(调用 push_up)
访问 子节点 之前 需要 向下传递懒标记(调用 push_down)
线段树基础题目合集
敌兵布阵 HDU-1166
I Hate It HDU-1754
A Simple Problem with Integers
Just a Hook HDU-1698